

เปิดโลก AI-in-the-Box
การปฏิวัติของ Large Language Models (LLMs) อย่าง llama, GPT, Deepseek และอื่น ๆ กำลังเปลี่ยนโฉมการทำงานในองค์กรทั่วโลก โดย AMD และ VMware ได้ร่วมกันออกแบบโซลูชัน AI-in-the-Box ที่ทำให้การใช้งาน AI แบบเต็มรูปแบบเข้าถึงง่ายขึ้น ด้วยสถาปัตยกรรมที่ทรงพลังจาก AMD EPYC 9004 Series ผสานกับ VMware vSphere คุณสามารถติดตั้งและรันโมเดล AI ได้อย่างรวดเร็วและยืดหยุ่นบนโครงสร้างพื้นฐานที่คุณมีอยู่แล้ว
ทำไมต้อง AI-in-the-Box?
- ตัดปัญหาการใช้ GPU
ใช้เฉพาะ CPU ของ AMD EPYC 9004 Series โดยไม่ต้องพึ่งพา GPU ราคาแพง
- เร่งความเร็ว AI Deployment
ด้วย vSphere + Ubuntu VM + Kubernetes คุณสามารถติดตั้งและรัน Llama2 ได้อย่างรวดเร็ว
- ตอบโจทย์หลากหลาย Use Case
- แชทบอทอัจฉริยะ
- การวิเคราะห์ข้อมูลอัตโนมัติ
- การสร้างเนื้อหา
- ระบบสนับสนุนลูกค้า 24/7
Success Architecture:
- AMD EPYC 9004 Series: โปรเซสเซอร์แบบ 96 คอร์ต่อ Socket ประสิทธิภาพสูง พร้อม Secure Encrypted Virtualization (SEV)
- vSphere: ระบบจัดการ Virtual Machine ชั้นนำ ที่รองรับทั้ง VM และ Kubernetes Cluster
- Docker & Kubernetes: เครื่องมือหลักสำหรับ Containerization และ Auto-Scaling
- PyTorch + Hugging Face Transformers: Framework AI ยอดนิยม ที่ช่วยให้การพัฒนาและ Deploy AI Model ทำได้ง่าย
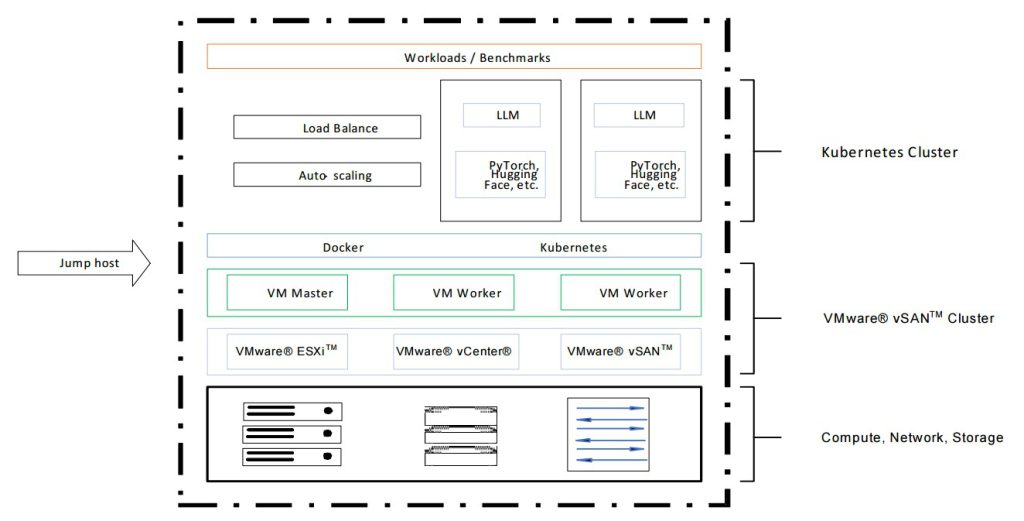
Design Objective:
- Load Balancer + MetalLB สำหรับจัดการทราฟฟิก
- Auto-Scaler เพื่อขยายและลดขนาดตามการใช้งานจริง
- ระบบ Storage แบบ vSAN เพื่อความเร็วสูงและปลอดภัย
Hardware and Software Architecture
ฮาร์ดแวร์ ต่อ Node:
- 2 x AMD EPYC 9654 (96 Cores)
- 1.5TB RAM
- NVMe SSD 8 ชุด (3.8TB ต่อชุด)
- NIC Mellanox 100 GbE
ซอฟต์แวร์ที่จำเป็นต้องใช้:
- vSphere 8.0 U2
- Ubuntu 22.04.4 VM
- Kubernetes v1.28
- Docker 27.x
- Llama2 (7B และ 13B)
Deploy: From Zero to AI Ready
- ติดตั้ง VMware ESXi และเซ็ตอัพ vSAN Cluster
- สร้างและติดตั้ง Ubuntu VM (1 Master + 4 Workers)
- ติดตั้ง Docker + Kubernetes
- ดาวน์โหลดและติดตั้ง Llama2 จาก Hugging Face
- ตั้งค่า Auto-Scaler เพื่อเพิ่มหรือลดจำนวน Pod อัตโนมัติ
- ตรวจสอบการทำงาน และทดสอบด้วยคำสั่ง curl หรือสคริปต์ Python
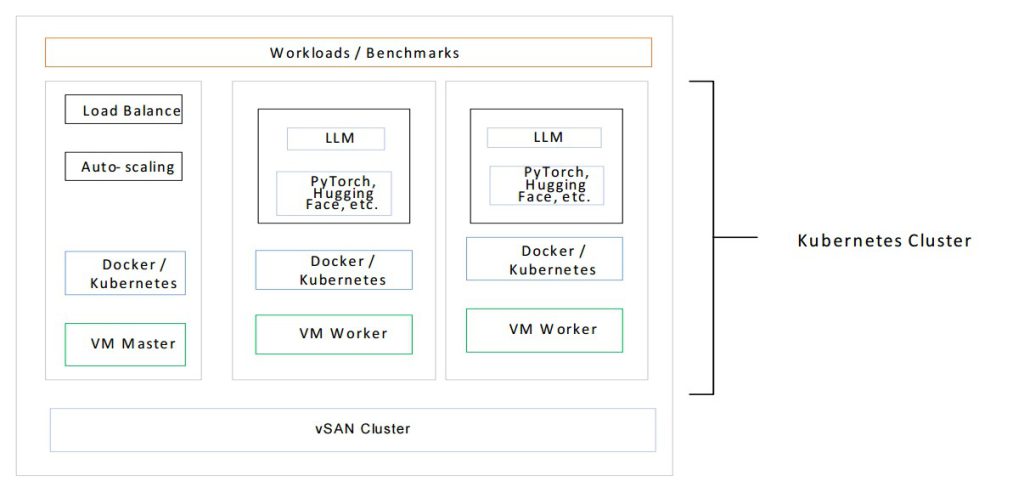
จุดเด่น
- รองรับการทำงานแบบ Real-time: ตอบสนองต่อการร้องขอของผู้ใช้งานได้อย่างรวดเร็ว พร้อมปรับขนาดระบบอัตโนมัติเพื่อรองรับโหลดสูง
- ขยายง่าย: จากการรันบน Single Node สามารถขยายไปยัง Multi-Node Kubernetes Cluster ได้ทันที
- เน้นความปลอดภัย: ฟีเจอร์ AMD Infinity Guard เพิ่มความมั่นใจในด้าน Data Security ระหว่างการประมวลผล
บทสรุป
โซลูชัน AI-in-the-Box จาก VMware และ AMD ช่วยให้องค์กรขนาดกลางถึงใหญ่สามารถใช้ LLM ได้โดยไม่จำเป็นต้องลงทุนกับ GPU หรือระบบซับซ้อน แค่คุณมี AMD EPYC Server + vSphere + ความรู้เบื้องต้นด้าน Kubernetes ก็สามารถเปิดประตูสู่โลก AI ได้ทันที นี่คือก้าวสำคัญที่ช่วยทำให้ AI อยู่ใกล้มือคุณมากกว่าที่เคย!
สัมผัสประสบการณ์ PROEN Cloud ได้แล้วที่นี่
📞 โทร: 02690 3888
📧 อีเมล: sales@proen.co.th



